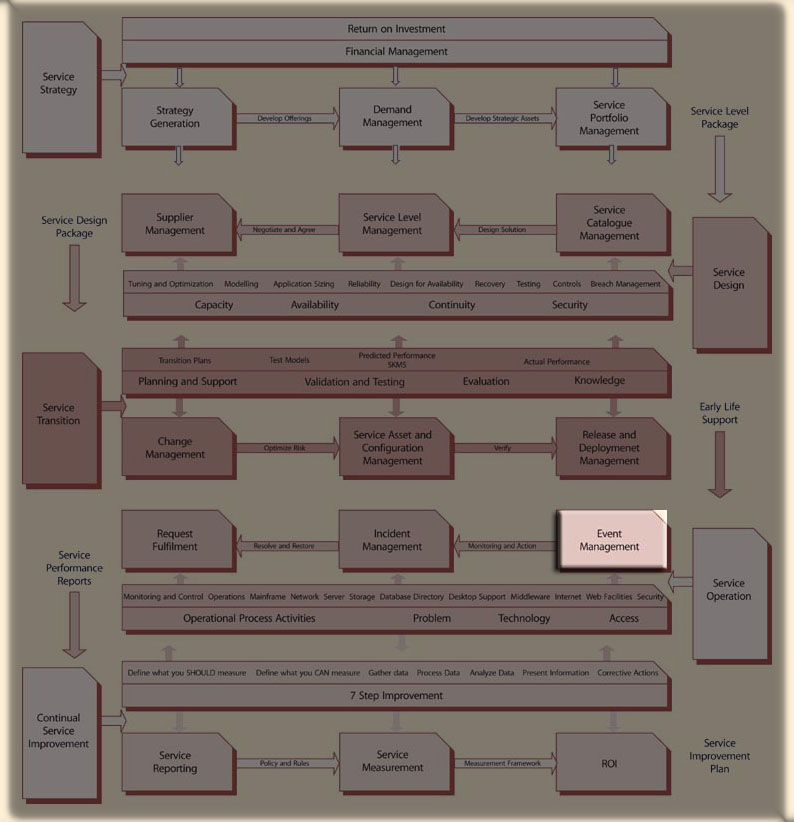
With the widespread use of distributed computing, the IT community has been faced with the difficult job of managing the support of IT services. Early efforts were ad hoc with multiple service organizations providing divergent services to client groups based upon divisions of the total infrastructure. Costs were high, service was inconsistent and users where frequently confused as to whom they should contact. To control the escalating costs and to invoke some order to an increasingly chaotic environment, IT departments have devoted renewed attention to IT support functions and have consolidated and developed standard processes and policies for supporting end users. Today, a consolidated IT Service Desk can offer a single point of contact for providing multiple IS services to the user community. By providing specialized and knowledgable advise and assistance as an initial point of contact, the Service Desk can quickly resolve many service requests expeditiously with minimal draw upon resources. Requests which require additional attention can be routed to the correct source(s) for treatment.
The Service Desk provides a vital contact point between business and technology clients, the IT Services Division and external support organizations. While Service Level Management is a prime business enabler for this function, the Service Desk acts has a key and primary role in the ongoing relationships with technology users by:
The Service Desk can effectively manage security by enforcing customer access requirements, removing terminated users, and serving as the single point of contact for customers. In addition, the Service Desk can document and sometimes resolve security events such as virus infestations.
The Service Desk is a primary user of the incident-tracking tool and the configuration management database (CMDB). The Service Desk uses these tools as a primary source of information to understand the environment when resolving customer issues. As the central, single point of contact for IT support, the Service Desk should be positioned to feed information to the incident-tracking tool and the CMDB. As the Service Desk staff resolves issues, they should update the incident-tracking tool with incident details, including resolution information. This information can prove invaluable for future reference by the entire IT support organization when resolving problems or evaluating the infrastructure.
Since volumes are small there are few incentives to implement a "managed" approach. Instead, the organization will adopt an "Immediate Response Model" -ie. call will be handled as they arrive.
With increasing volumes, there will be a need for determining the urgency and priority of incidents according to the business importance of the components experiencing difficulty. So, there should be a basic inventory of CI. This may take the form of an Excel spreadsheet listing all devices and their locations. More sophisticated implementation may attempt some rudimentary assessments of other configuration items which will be impacted by the listed device. Since the total volume is relatively small this inventory is controllable.
Maintaining the inventory will, of course, be problematic and probably beyond the scope of the Service Desk staff. Instead, it will be periodically updated as an assigned duty (say, monthly) and ancillary information such as the number of incident or changes to a device will not likely be recorded.
There are a number of Incident recording systems ideally suited to small organizations. At this scale they will typically be based upon an MS Outlook or MS Access form. there are Service Desk products available very cheaply based on these products. They do not scale well, nor are they well integrated with other service management areas. They do, however, provide rudimentary capability at a small cost and are a large step up from manual procedures.
As the organization get larger there are economies to be achieved through subject matter specialization. The organization develops specialized knowledge in such areas as desktop, network and application support. Or, rather than volume, a large, diverse product base will add "complexity" to the environment which will tax the ability of service agent's to remain knowledgable in all product lines. It is usually considered good practice to limit the number and range of similar product offerings. Both Gartner and META research advocate maintaining a discrete product line as a key factor in reducing support costs.
The benefits associated with an effective knowledge management process are many. Some
examples of these include:
Knowledge management must begin with achievable goals and clarity of objectives and language
to facilitate success. The implementation of this process should be broken down into
manageable stages with a general timeframe for implementation, including organizational
support, defined roles and responsibilities, established standards for the knowledge architecture,
and culture of sharing and using knowledge.
Best practice organizations document the problem resolution workflow. To better control costs,
the information in the knowledge database must be updated to ensure accuracy. Ensuring that
controls are in place to keep information updated is critical because knowledge will frequently
change. The procedures for handling these changes needs to be documented clearly and
distributed. Determine also if the knowledge needs to be formatted into cases before it is used or
is there some other type of documentation for training materials, procedures, etc. that the
organization is familiar with that can be leveraged. If the overall knowledge management
process is done well tha maintenance process should be simple. Maintenance involves
correcting, refining, and expanding the knowledge base should be a single step reducing the
lapse time between discovery and publication. In summary, the key best practices previously
discussed include:
In addition to self-help, the adoption of self-healing has become more widespread among self-
help capable systems. These are tools that maintain a root understanding of the distinct system
and desktop profiles and can restore or heal to a functioning state. Registry settings and key
application executables must be maintained in a desired desktop environment which, when
corrupted, can be reset either automatically and independently of the IT service desk.
It is highly beneficial for the Service Desk infrastructure to allow the storage, archival, and easy retrieval of the
comprehensive customer interaction history. The Service Desk can use this information for queries, analysis, and reporting to align your strategic and operational decision-making processes with the feedback that you have received from your customers. Every interaction with the customer is an opportunity to know them better.
Intelligent routing determines which service desk agent should receive which e-mail based on
skills and expertise area. Intelligent routing also allows for the use of prioritized routing rules to
streamline or slow down e-mails in the queue based on who the customer is and the text
contained within the message. Auto Response is the second component which is an automatic
suggest function where an automatic e-mail is sent in response to a customer with suggestions on
how their problem can be handled. The auto response sends a standard message of
acknowledgement and the auto suggest sends suggested steps for resolution to fix the customer
problem. E-mail monitoring allows the manager to establish the rules, which monitor outgoing
e-mails. If the subject or content of the e-mail falls within the boundary of the rules, the e-mail
can be sent to the manager first rather than the customer for auditing purposes.
ERMS and IVR have traditionally been found in mid-size to large organizations in the United
States and have been growing within small organizations for several years.
The practices mentioned in this section describe the key operational components of the Service
Desk. These are the near-term elements that must be built into the service desk to provide
internal support to users and the business. In addition to these near-term elements, one must
considered longer-term evolutionary phases defining where and how organizations are beginning
to transform the service desk. The next section describes the longer-term view of how the IT
Service Desk and Customer Service and Support people processes and technologies will work
together.
Note: that the Incident Coordinator does not need to be technically specialized. In essence, the Coordinator frees the Incident Analyst/Situation Manager of administrative functions thereby allowing them to devote more of their effort to the restoration undertaking.
| Term | Definition
|
| Abandon Rate | The percentage of total calls received that self-release from ringing or queue before reaching a support team member.
|
| Agent | A common term used to indicate a Help Desk or Support Center employee whose primary job responsibility is responding to customer calls. These employees typically provide first-level or second level support.
|
| Architecture | An organized framework consisting of principles, rules, conventions, and standards that serve to guide development and construction activities such that all components of the intended structure will work together to satisfy the ultimate objective of the structure.
|
| Asset Management | Implementing a set of operating and accounting procedures intended to maximize the return on investment (ROI) of the equipment assets of an organization, especially capital assets.
|
| Assignment | The process by which the responsibility for taking the next action for managing and resolving a customer service request is designated to a specific individual, function, or organization. Typically, the Help Desk or Customer Support Center continues to monitor the service request and tracks it until the request is closed.
|
| Auto Attendant | A system that allows callers to route their calls to a known telephone extension number or obtain the desired extension number from the system. A touch-tone phone or speech recognition system is required. This feature is typically integrated with an automatic call distribution (ACD) system.
|
| average length of call | The average time required to process a customer call, from initial receipt to final closure, including both on-phone and off-phone time.
|
| average speed of answer (ASA) | The average time required for an analyst or an appropriate automated response tool (such as an IVR) to respond to an incoming call.
|
| average talk time (ATT) | The average time per call that an analyst spends actually talking with a customer on the phone. This is a common ACD statistic.
|
| average wait time | The average length of time a caller holds before abandoning the call or being helped by an agent. Also called average hold time.
|
| Baseline | A standard for comparisons. A baseline is a reference position for measuring progress in process improvement. The baseline is usually used to differentiate between a current and a future representation.
|
| Benchmarking | A method of measuring processes against those of recognized leaders. It helps establish priorities and targets leading to process improvement.
- Identification: It is undertaken by identifying processes to benchmark and their key characteristics;
- Determining who to benchmark;
- Collecting and analyzing data from direct contact, surveys, interviews, technical journals, and advertisements;
- Determining the "best of class" from each benchmark item identified;
- Compare the Process to the Benchmarks: Evaluating the process in terms of the benchmarks;
- Setting the improvement goals.
|
| Best Practices | A way or method of accomplishing a business function or process that is considered to be superior to all other known methods.
|
| Bulletin Board | A display, usually placed strategically throughout the customer support area as well as customer areas and used to notify personnel of problems or the current status of systems.
|
| call cycle time | The total time required to process a customer call, including call logging and initial diagnosis, research, resolution, follow up, and closing the call. Note that the term call cycle time limits reporting to calls only versus all service requests.
|
| call resolution rate (CRR) | The percentage of calls captured that are resolved within each support level or by the Help Desk or Customer Support Center overall.
|
| call routing | The processes used to transfer a call from one individual, function, organization, or location to another either by a Support Center employee or automatically, based on a set of predefined rules.
|
| call screening | The process of collecting information from the caller including name, phone number, location, and specific request for service, then routing the call to first-level support.
|
| call volume | The total number of inbound and outbound calls within some meaningful timeframe or category.
|
| calls per agent | The average number of calls received by an agent within some meaningful timeframe or category.
|
| calls per period | Call volume per time period. Typical time periods Help Desks or Customer Support Centers report on include hour, shift, day, week, month, quarter, and year.
|
| Category, Type and Item (CTI) | Method for Classification of a group of Change documents according to three-fold hierarchical coding structure used by many organizations.
|
| Change | Any action resulting in a new status of one or more of the Configuration Items.
|
| Change Advisory Board (CAB) | A group of people who can give expert advice to the Change Manager on the implementation of Changes. The rigor with which changes are considered is determined by the evaluated risk associated with the change. The degree of risk (as well as customer concerns and financial considerations) will determine the authority charged with approving changes into the infrastructure.
These bodies are:
|
| Change Calendar | A documented record of the sequence of steps involved in building a release (implementing a change).
|
| Change Management | The policies, procedures, and business practices used to control and introduce change into a technical and business environment, such as hardware and software upgrades.
|
| Configuration Item (CI) | Component of an infrastructure - or an item, such as a Request for Change, associated with an infrastructure - that is (or is to be) under the control of Configuration Management.CIs may vary widely in complexity, size and type, from an entire system (including all hardware, software and documentation) to a single module or a minor hardware component.
|
| Configuration Management Database (CMDB) | A database that contains all relevant details of each CI and details of the important relationships between CIs.
|
| Coverage | The normal hours of operation of a support organization.
|
| Customer | Any person who comes in contact with a Help Desk or Support Center employee in person, over the phone, via e-mail, or by other communication channels. Customers may be internal (employees of the company) or external (people outside the company who request information or help).
|
| Customer Interface | The tools and techniques the customer and Help Desk or Customer Support Center use to communicate, such as the telephone, e-mail, fax, direct access, or call management system.
|
| Decision Tree | A type of expert system comprised of a branching structure of questions and possible responses designed to lead an agent to an appropriate solution to a customer's problem or provide needed information. Decision-tree structures resemble an organizational hierarchy. Decision trees are most appropriate where the problem type is broad and shallow. Decision-tree systems work well for entry-level agents, because they walk the agents through specific questions and answers. However, senior agents may not want to step through each branch, since they usually know some of the questions and answers; they may feel that working through the tree process actually slows them down
|
| Diagnose | Determining the cause of a problem or type of information needed and the actions that must be taken to resolve it.
|
| Diagnostic Aids | Diagnostic tools such as error log interpreters, crash analyzers, or network monitors that assist the Help Desk agent in rapidly isolating the cause of a caller's problem.
|
| Dispatch | A call management function in which Service Desk or Customer Support Center agents determine whether the caller is entitled to service, determine the nature of the problem or type of information needed, log the call, and route the caller to the first level support function. This function is frequently automated through the use of ACD systems.
|
| Emergency Change | Used for production changes that have a business or system driver that requires immediate implementation, regardless of time. This occurs when the business risk of not changing the production environment out-weighs the risk of making the change and the change cannot wait for the next standard Release Date.
|
| Environment | A collection of hardware, software, network and procedures that work together to provide a discrete type of computer service. There may be one or more environments on a physical platform e.g. test, production. An environment has unique features and characteristics that dictate how they are administered in similar, yet diverse, manners.
|
| Escalation | A defined management process in which a service request's priority is changed due to the impact or timing of the request, customer input, or duration. Escalation is a management process for giving a call more priority; urgency, or resources. Though often used interchangeably with elevation, the escalation process differs from elevation.
|
| Expert System | A type of knowledge-based system that processes information in an area of expertise and performs functions in a manner similar to a human who is expert in that field. An expert system can solve problems by drawing inferences from a collection of information that is based on human experience and problems the system has previously encountered. Expert systems diagnose the problem, then advise the customer on how to correct the problem. Most expert systems fall into three categories: case-based,decision tree, and rules-based systems.
|
| FIFO | First-In / First-Out: A queuing technique that assures the next item or person to be handled is the one that has waited the longest. This is the technique most Help Desks and Customer Support Centers use. It is typically automated by using ACDs.
|
| Generalist | An agent with broad knowledge of a range of technologies or subject areas. Many first-level support agents are generalists.
|
| Handshake | The formal process of one support level or function transferring a service request to another support level to ensure the request remains assigned until resolved.
|
| Impact Analysis | A quantitative research method in which a study is conducted into the effects that an error may have on the other parts of the configuration and the subsequent consequences for the service level, taking into account the risks of such an error occurring as well as the severity of the error.
|
| Incident | Any event that is not part of the standard operation of a service and that causes, or may cause, an interruption to, or a reduction in, the quality of that service.
|
| Infrastructure | The sum of an organization’s IT-related hardware, software, data communication facilities, procedures, documentation and people.
|
| IVR | interactive voice response: Systems that allow callers to input information into a touch-tone telephone, get a response from the computer, or perform an action based on choices the customer makes. IVRs are typically integrated with other telecommunications systems.
|
| Knowledge Base | An accumulation of data or history from and/or for support issues.
|
| Known Error | A condition in the IT infrastructure in which a certain Configuration Item has been identified as the cause of a (potential) degradation in the service level agreed upon.
|
| LIFO | A queuing technique in which the next item or person to be handled or retrieved is the item most recently placed in the queue.
|
| Log | To formally record basic information related to the receipt of a new service request, usually in a computer-based problem management system.
|
| MTTR | meantime to repair: Average length of time for problem resolution.
|
| Objectives | Quantified, specific statements noting what the Service Desk or Customer Support Center will accomplish, such as /11 reduce total cost of support by 15%" or "decrease customer downtime by 25 hours per quarter."
|
| Open Requests | Service requests received and logged but not yet resolved; the difference between the number of calls logged and the number of calls closed.
|
| Ownership | Usually used in the context of the Service Desk or Support Center agent who is assigned to the service request until satisfactory resolution is met, regardless of where the service request has been assigned.
|
| Priority | The relative assessment of an activity in relation to other activities. The characteristic of preceding, or having priority over, something or someone else. Priority consists of impact, urgency and expected effort.
|
| Problem | A condition of the IT infrastructure that is identified through incidents with similar symptoms, or a significant incident that is indicative for an error of which the cause is not yet known.
|
| Process | A connected series of actions, activities, Changes etc. performed by agents with the intent of satisfying a purpose or achieving a goal.
|
| Process Control | The process of planning and regulating, with the objective of performing a process in an effective and efficient way.
|
| Protocol | Specifications describing the rules and procedures that products (such as fax machines, modems, and servers and clients) should follow to communicate with one another or to perform functions on a network. If products from different manufacturers use the same protocols, the devices can communicate.
|
| Queue | A "waiting line," such as for problem reports that agents will handle. Items can be queued for processing within a computer, or customers can be on hold in a telephone queue.
|
| Release | A collection of new and/or changed CIs which are tested and introduced into the live environment together.
|
| Request for Change (RFC) | Form, or screen, used to record details of a request for a Change to any CI within an infrastructure or to procedures and items associated with the infrastructure.
|
| Risk | A measure of the exposure to which an organization may be subjected. This is a combination of the likelihood of a business disruption occurring and the possible loss that may result from such business disruption.
|
| Role | A set of responsibilities, activities and authorizations.
|
| Service Level Agreement | A written agreement between a service provider and Customer(s) that documents agreed services and the levels at which they are provided at various costs.
|
| SME | Subject Matter Expert - A support resource highly knowledgeable in the infrastructure components undergoing a change.
|
| System | An integrated composite that consists of one or more of the processes, hardware, software, facilities and people, that provides a capability to satisfy a stated need or objective.
|
| Transfer | Passing an incident to a more capable resource after some preliminary handling.
|
| Urgent Change | An Urgent Change is used for production changes that have a business or system driver that requires immediate implementation, regardless of time. This occurs when the business risk of not changing the production environment out-weighs the risk of making the change and the change cannot wait for the next standard Release Date. A change is considered Urgent if there is a significant detrimental impact to the customer experience (external to the organization), with no reasonable workaround, and the issue causes a financial impact AND/OR the issue keeps one or more people from doing their job. An Urgent Change requires the approval of Corporate Emergency CAB.
|
| User | The consumer of IT services. This consumer may originate from any of the managerial or operational levels of the organization.
|